注:范特西是一款挑选球员,以现实比赛数据为基础,在虚拟世界进行对抗的游戏。
在NBA的2022-23赛季开始前,作为范特西玩家的我们又开始准备了一年一度的报告。
你可以把这看作是对上赛季的总结分析,也可以当作是对接下来新赛季的展望,希望我们的一些总结和分析,能够对各位新赛季的范特西选秀带来一点帮助。
废话不多说,请各位先看下面这张图表。
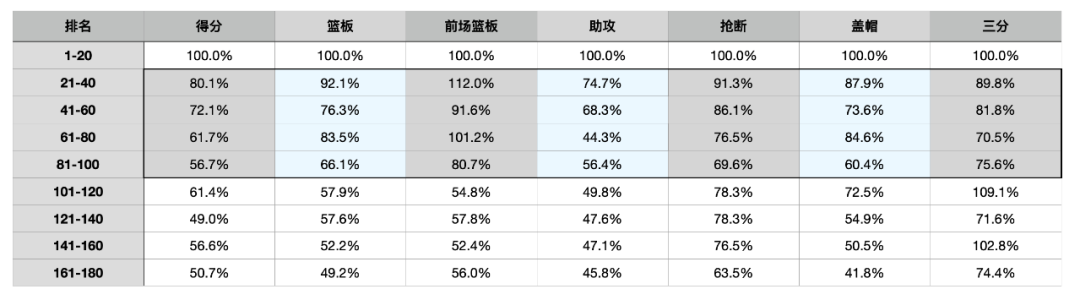
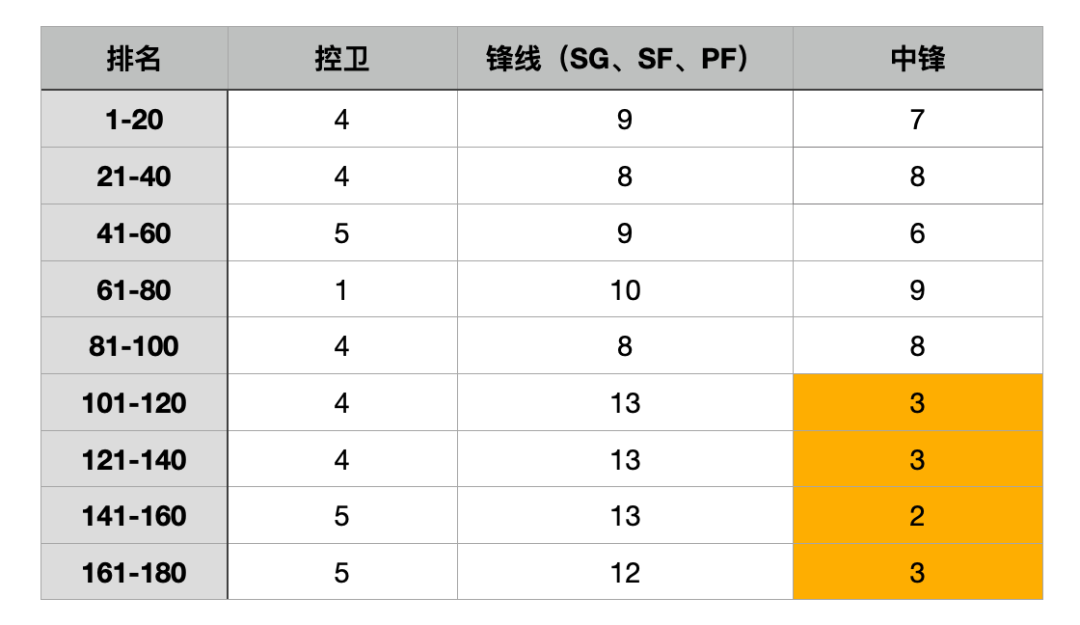
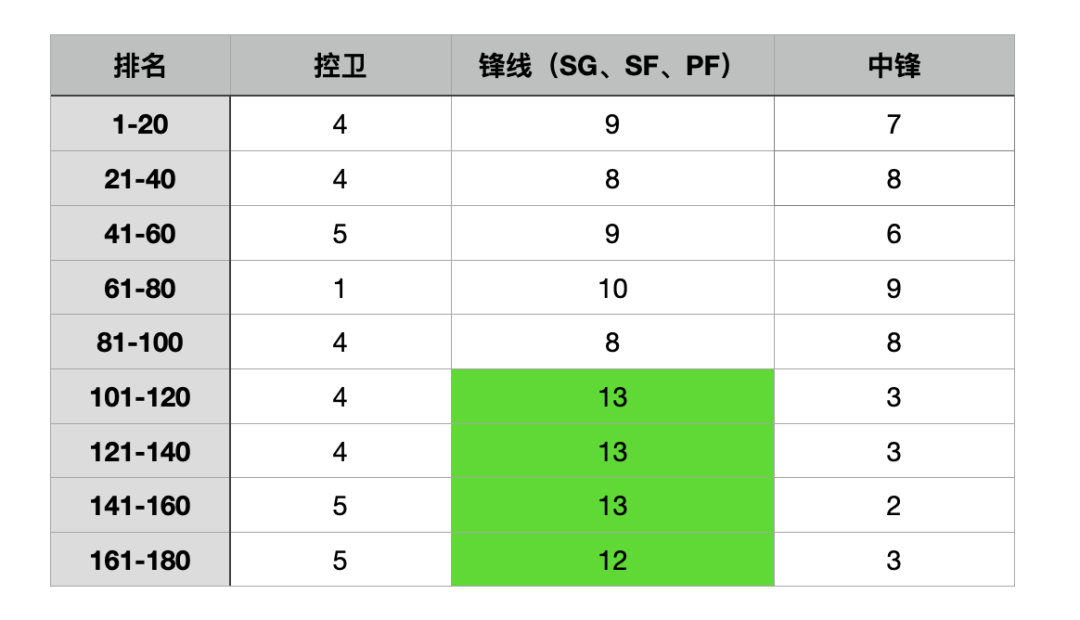
这是结合上赛季BBM的球员排名和出勤率所制作的数据图表,然后我们就像过去几年,利用这份数据总结了各个排名段球员生产数据的具体情况。
不过,和以往有出入的是,这次我们把排名段位分得更细一点,以每20名作为一档,也顺应20名球员为一轮选秀的结构。这样也能更好地把“首轮球员”作为我们锚定的基石,体现出“每一轮球员与首轮球员之间的差距到底多大”?
我们取每一轮的20名球员的平均数据进行对比,然后把1-20名的球员作为基石,看看往后数的每一轮球员平均数据可以做到首轮球员的几成?
接着,可以把每一轮次百分比三个最低的数据项做一个标记,赋予不同深浅度的颜色记号,然后看看哪个数据项目深色格子最多,便是与首轮水平相差最多的项目。
从这个图表中不难看出,“助攻”这一项数据喜提最多的深色格子,这意味着助攻是“非首轮球员”最难与“首轮球员”媲美的数据。
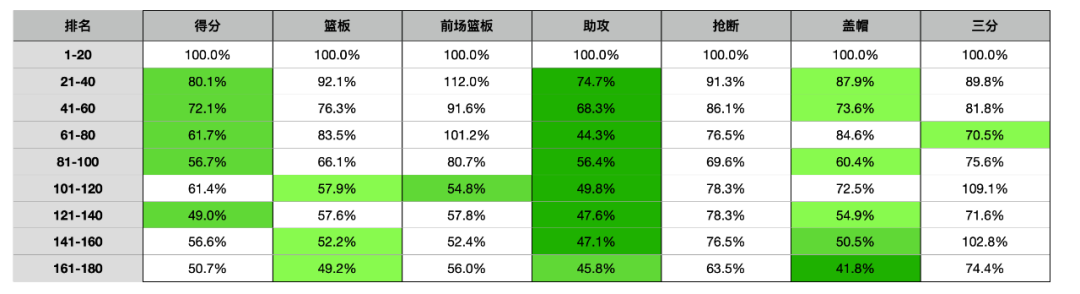
你看,在21-40位,这一相对较高的分段,生产助攻的效率就已经掉到了74.7%。
而在61-80,大概在4轮的位置就只剩下44.3%,这一断崖式的效率下滑,足以看出“助攻”数据的稀缺度。
而这与我们去年的统计出现了明显的差异,当时稀缺度最高的三项数据依次是——命中率(今年我决定把命中率单独拿出来说)、前场篮板、篮板。助攻只是在中等偏上的位置。
20-21赛季首轮球员平均每人的助攻在4.57,而21-22赛季提高到了5.46。
20-21赛季首轮球员里助攻最高的只是9.43的特雷-杨,而21-22赛季助攻9+的球员就有3人:哈登、特雷-杨、德章泰-穆雷。

这三人有一个共同点,那就是球权绝对集中的核心,这大概为我们解释“助攻”的稀缺度变化提供了一个思路——现实世界篮球的大核心趋势映射在了数据层面,球权越来越集中到某些“最佳球员”手里(同时这些最佳球员也能干别的事情,数据的多样性让他们坐稳首轮),从而导致助攻大量集中到“首轮球员”身上的现象。
上赛季的新晋首轮球员,哈利伯顿、穆雷、三球,都符合“大核”的概念,他们取代了表现下滑的“全能内线”(兰德尔、阿德巴约、武切维奇)。

而有趣的是,“全能内线”的表现下滑与他们战术角色被稀释有关,因为他们其实无法完美执行“全能内线”的工作,优秀的全能内线固然能为球队带来极高的提升,但半吊子对球队是弊大于利,毕竟约基奇可没那么好当。
但“外线大核”不一样,他们更容易打出可观的下限,然后球权和战术角色相应增加,数据也因为球权的增加而水涨船高,进入美妙的循环。
简单来说,“外线大核”和“全能内线”不同的性价比,正在渐渐改变现实世界的篮球偏好。
由于激励影响生产关系,而当一个角色被重视,他又能得到更多的出场时间,出场时间又是生产数据的基本要素,数据也就因此改变,最后这种改变投射到虚拟世界,也就导致了整个数据结构的变化。
我们可以继续看这个数据模型向我们展示了什么东西,这些颜色标记大多依次集中在:助攻、得分、盖帽。
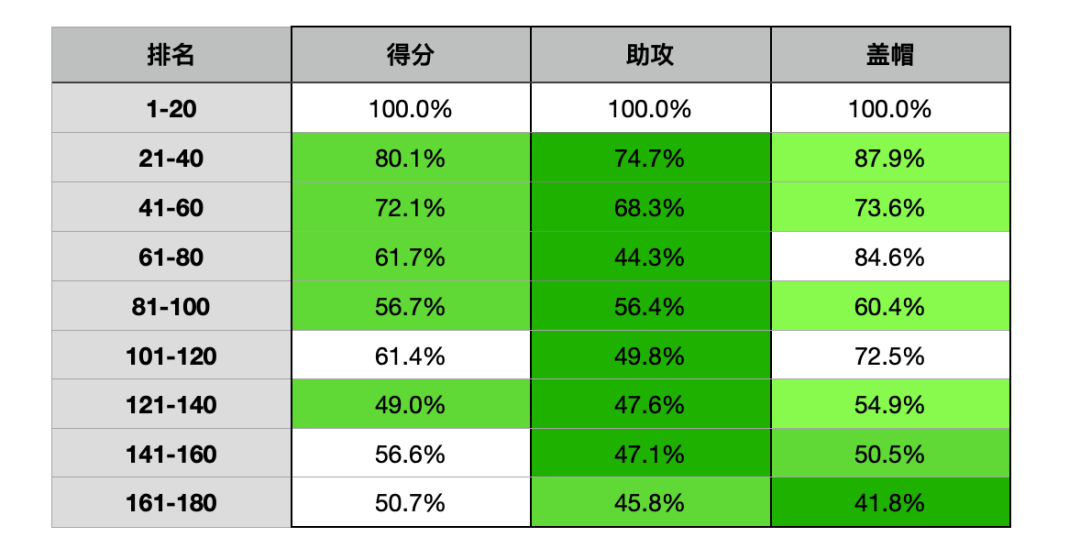
你可以把这3样数据排列组合,互相搭配。然后你会发现,得分-助攻是相关性最大的一对组合,同时生产得分和助攻的球员不少,但同时生产得分-盖帽、助攻-盖帽的球员,好像不多吧?
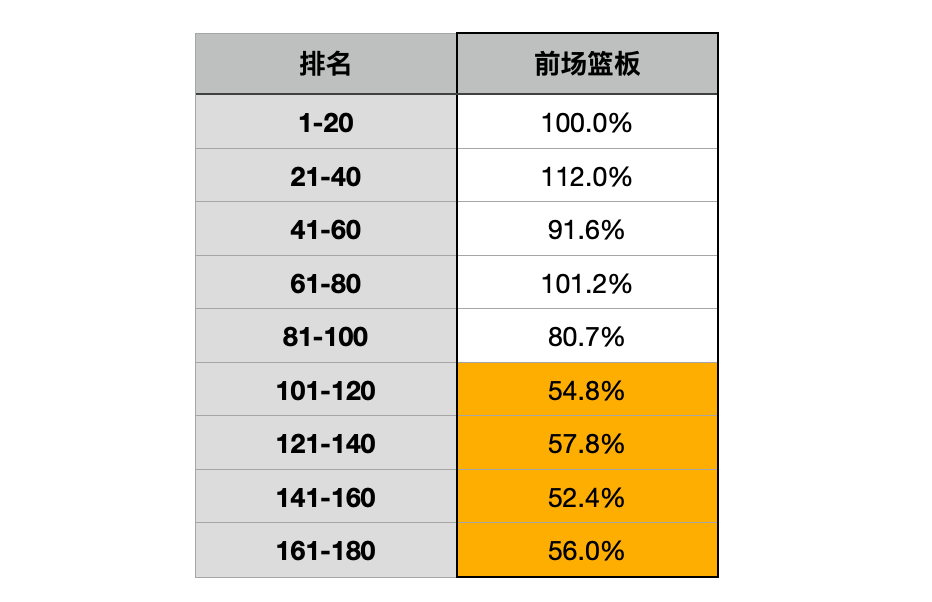
这也就能解释一个问题——“助攻”的稀缺度上升了,后卫在中高分段的分布理应更多,中锋理应相应变少,但实际上这样的变化并不明显。反而,前100分段的中锋人数从上赛季的24增加到38。
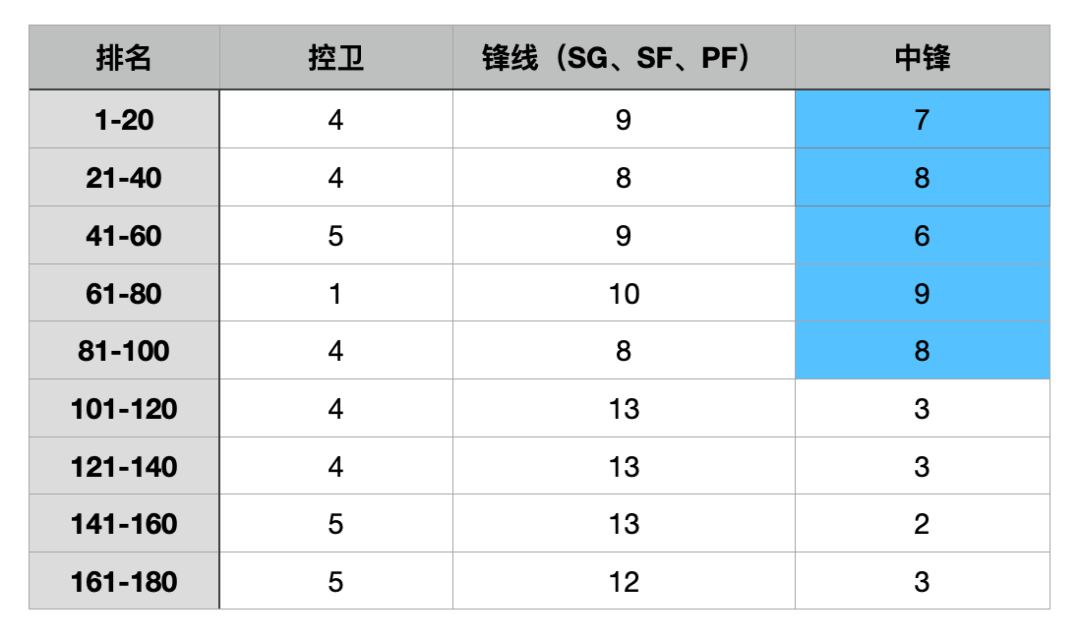
这大概是由于,盖帽仍然是一项较为稀缺的数据,尤其是既能得分又能盖帽的内线本就是“相关性较弱”的类型,毕竟“有球权”和“蓝领工作”通常是相悖的。
而全联盟场均10分+1盖帽的球员,就只有22个而已,而且其中除了勒布朗-詹姆斯、杰拉米-格兰特、贝兹利,都是内线(如果你认为偶尔摇摆到3号位的克拉克不算内线,那么就是18个内线)。
所以,我们可以在统计中发现,中锋在中高分段的分布仍然坚挺,并且在100名之后出现了明显的落差(前场篮板数据也在100名之后出现了明显的落差)。
以此,我们也许可以提出一个假设——那些与“高稀缺度数据”相关性高的球员,是不是更值得选择?
比如,那些能够同时贡献得分、助攻、盖帽的球员,不就是优先级最高的选择吗?
你看,上赛季BBM榜单的两座大山就是三名“既能得分,也能助攻,又能盖帽”的全能内线,而他们远远甩开其他人一个身位。
约基奇和恩比德各自以2.48和2.23的分值高居第1、2位(如果字母的罚球不那么差,那么他应该也是“2分俱乐部”成员)。另一位全能内线唐斯在第3,他的分数也高达1.97。
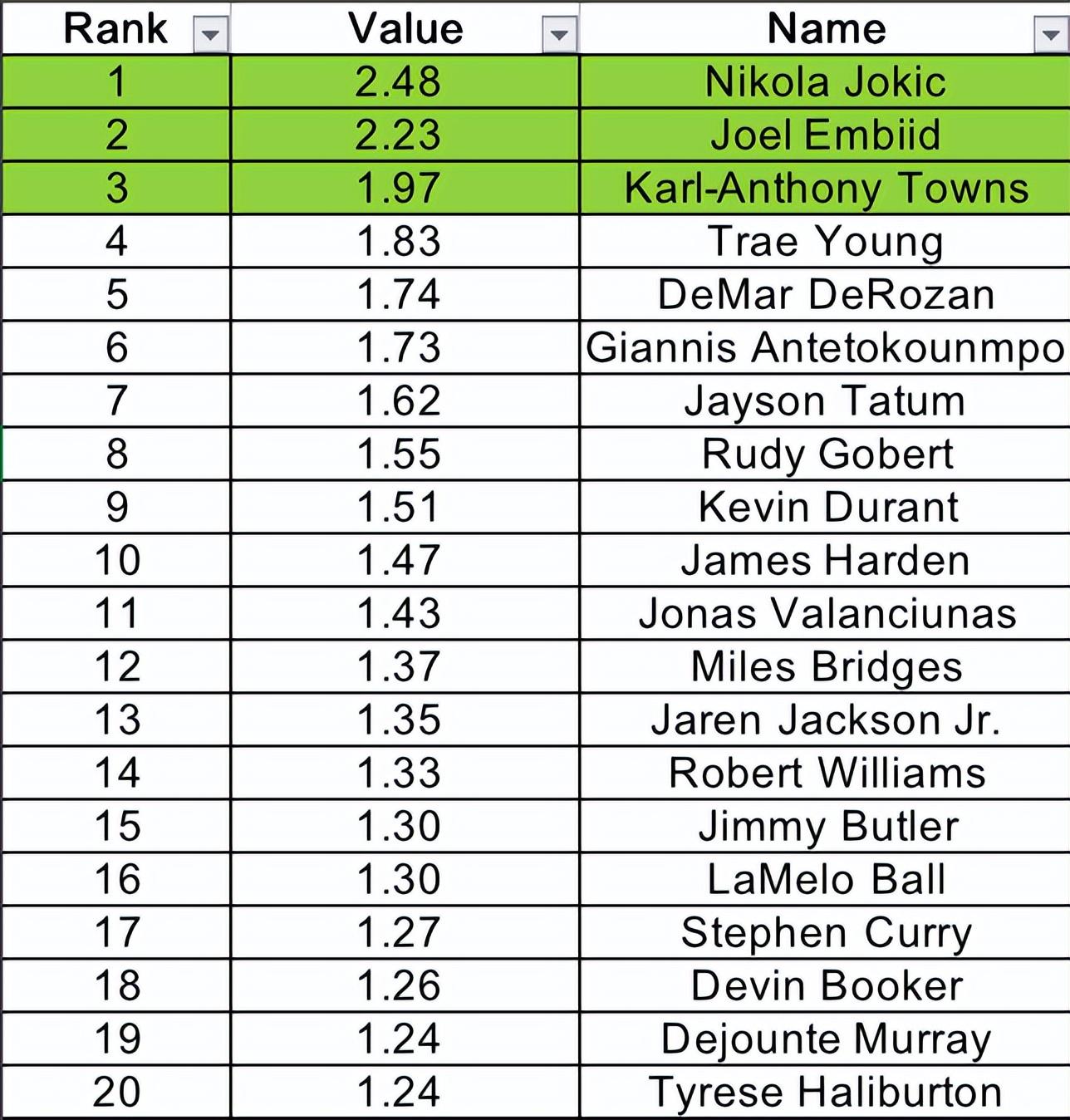
当我们把一名球员叫作全能内线,意味着他能够得分、篮板、助攻、投篮、抢断、盖帽一把抓,而这样什么都能干的球员就应该在范特西里吃香。
同理,一个本就天然能得分助攻、还有一点儿副业的后卫(比如穆雷、哈利伯顿、三球),也同样讨喜。
反过来说,那些与“稀缺数据相关度低”的球员,就不值得大家重仓。
比如,这个联盟存量最多的锋线,由于基数太大,导致他们的基本盘“三分”和“抢断”泛滥,让这两项数据的稀缺性变弱。
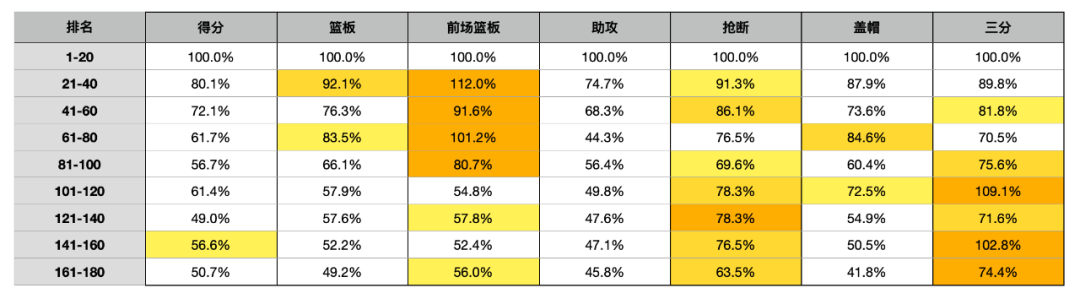
同时受限于职责,锋线平时的球场任务又与“助攻”和“盖帽”相距甚远,除非是那些有球权在手的明星前锋,否则前锋大多都身价有限。
从图表中你也可以看到,100名开外的分段,锋线所占的比例开始明显变多了。
“1+1=2”
把“两项命中率”单独拎出来说的原因很简单,因为这是高分段与低分段落差更大的项目。
从图表中不难看出,命中率在40名开外已经要打对折,而罚球命中率更是在20名以后几乎都是拖后腿的存在了。
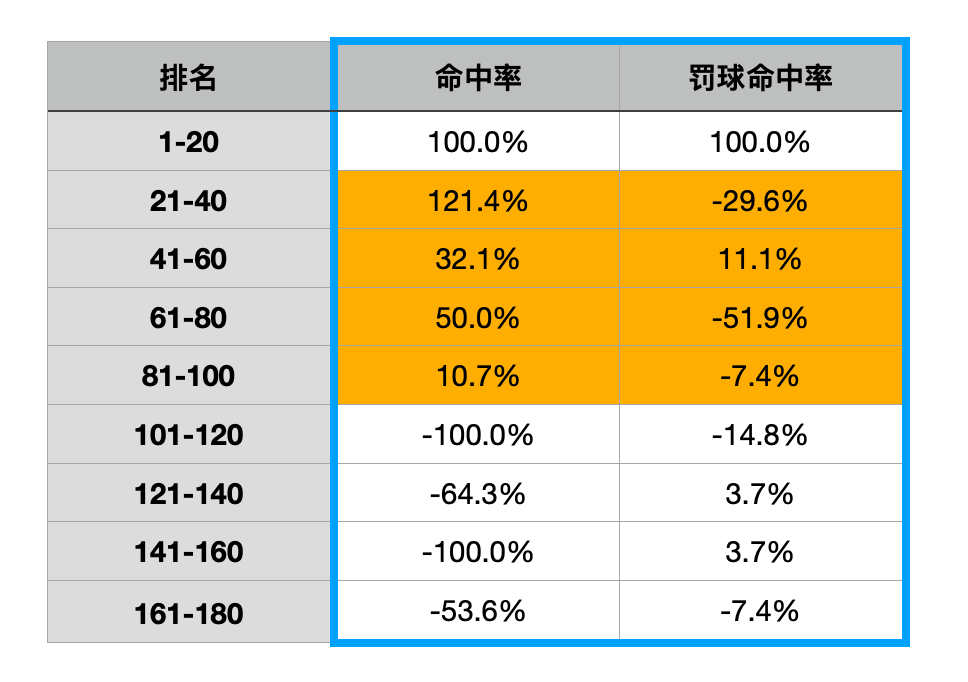
因为两项命中率的统计有些不同,因为这不仅比谁更准,还是比谁投的又多又准。而球权又只会在核心的手里,某些角色球员虽然准,但因为很难捞到足够形成质变的出手数量也无济于事,只能做到不拖后腿而已。
我们可以做一个简单的计算,整个联盟有30支球队,假设每支球队有1名核心,那就是有30个可以大量出手的球员,那其中有多少人能做到又多又准呢?
就算条件放宽,假设每队有2名核心,那也只是有60个可以大量出手的球员,如果其中有一半人能做到又多又准,也只是30个而已。
所以,就不难理解为什么“两项命中率”会出现如此之大的落差。

反过来说,在你敲定“首轮球员”的那一刻,似乎也就确定了你在“两项命中率”的数据上是否存在优势。如果你在前两轮选到无法在两项命中率建立优势的球员(比如德章泰-穆雷、东契奇),那么也很难通过后面的操作去补救。
由此我们也不难理解,围绕首轮、或者前两轮球员建队的重要性。
高分段球员就是球队的骨架,因为他们能在更多项目建立优势。而后就是要顺着骨架生长,而不是强行改道。
所以,相性兼容有时候比是否捡漏更关键。不能为了捡漏而捡漏,明明球员A更适合搭配球队,但我在100顺位选了值50名的球员B,可是球员B的数据并不是球队需要的,那这样的决策显然是欠妥的。
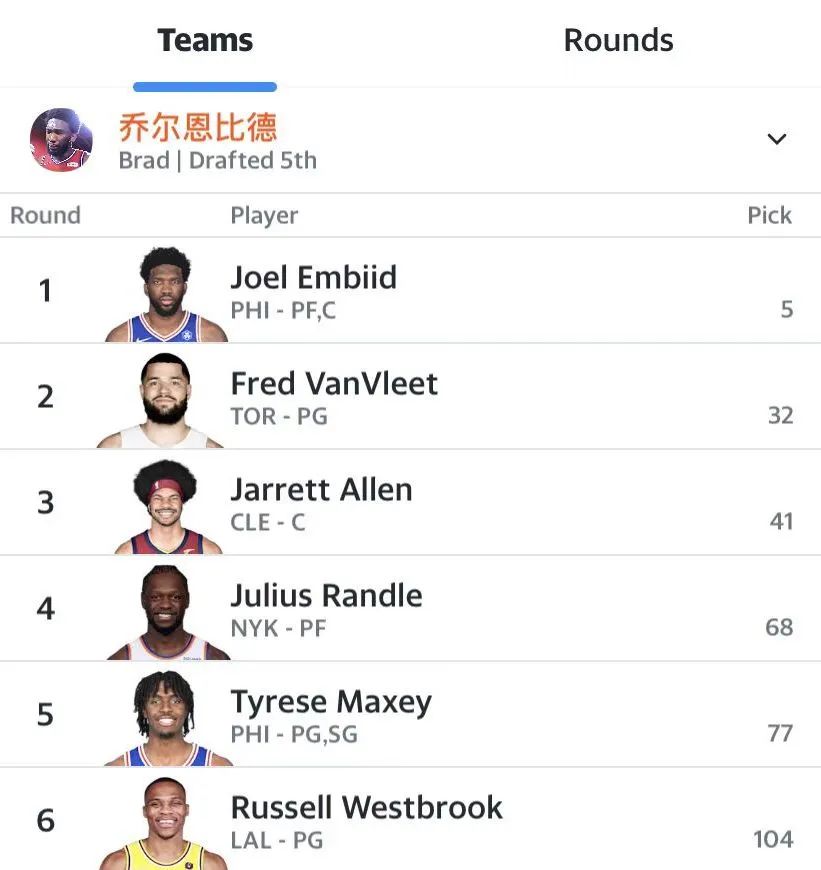
我最近的一次选秀就可以作为各位的反面教材,我在第一二轮的选择是恩比德和范弗利特,但我在后续的选秀中却为了加大输出,选了拖罚球后腿的贾莱特-阿伦、兰德尔和威少,给本来可以稳稳拿下的“罚球命中率”增加了不确定性。
恩比德和范弗利特合计对“罚球命中率”的贡献是0.998,但阿伦、兰德尔和威少三人加起来对这项数据的影响却是-1.1,这不就浪费了恩比德和范弗利特独特的“罚球命中率”优势,白白送掉宝贵的1分吗?而在后期补“罚球”这1分的难度,远比补其他数据来得更难。
所以,要重视首轮球员的长处,并且围绕其组建球队,才能发挥每一个首轮球员具有的独特竞争优势。
除非,你运气爆棚,上演妙手生花的剧情,能够在低分段淘到各种高质量球员,这样的话阵容搭配于你而言就是浮云……
“隐藏的重要指标”
从上一个章节我们已经论述过“首轮球员”有多么重要,那反过来说,如果前两轮选得不好,那真的是要白白浪费一个宝贵的赛季。
上赛季如果谁选了利拉德,那他的范特西之路显然会异常艰难。鉴于利拉德20-21赛季的结算顺位仅次于约基奇,21-22赛季玩家们平均在第7位就挑走了利拉德。可是,利拉德并没有打出符合身价的表现,最终赛季结算时只排在第216位。
同样的情况还在戴维斯、乔治、比尔身上出现,三人平均被选走的顺位依次是13、13、14,但最终只排在71、199、172位。
而他们都存在同样的情况,那就是受伤病影响,四位球员之中出勤最高就是40场而已。

所以,这个游戏还有一个相当关键的隐藏指标,“出勤率”。
出勤率的高低能让珍稀的首轮变成不起眼的FA,也能让不起眼的FA变身为珍稀的首轮。它对于我们挑选球员有着重要的影响。
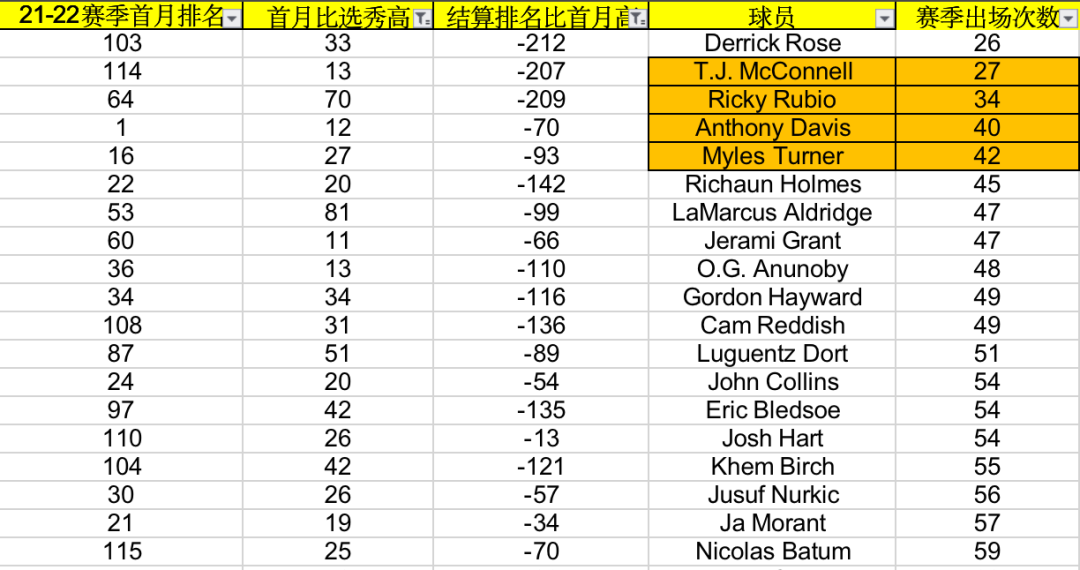
上一次报告我们提到过范特西选球员应该和现实世界反着来,更应该“追涨杀跌”(因为范特西是一个20周的零和博弈,时间成本也相当重要),所以我们可以做一个“追涨”的小测试。
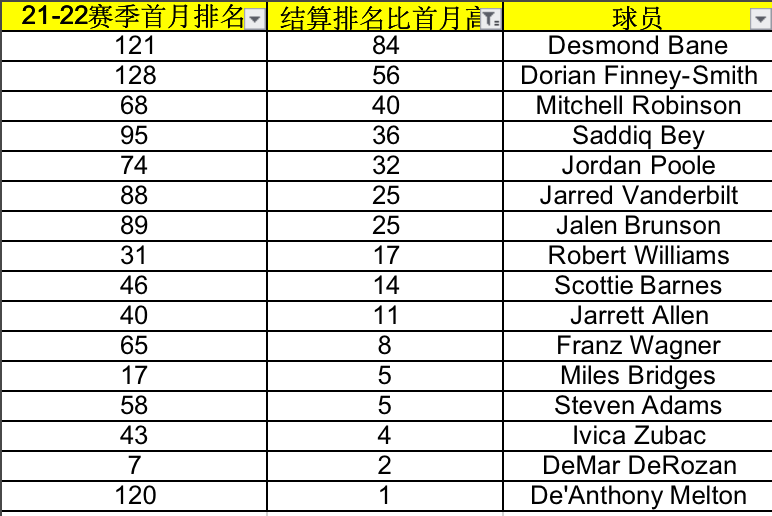
选出上赛季首个月比赛打完后比选秀顺位高10位的球员,总共有63名球员(由于BBM对选秀顺位的统计最低到148,所以这里面的样本是选秀顺位高于或等于148的球员),然后再看他们赛季结算时的排名,其中只有16人能够保持这个“上涨”的趋势到赛季结束。
这说明你追涨的成功率大概只有16/63,约等于4分之1。如果去掉像德罗赞这样难以流通的高分段球员,实际的数字还要再降。
那么,是什么造成了两批球员的分化?也许就是“出勤率”。
因为有一个差异很大的指标,这16名成功身价上涨的球员,赛季出勤率平均下来是74.4场,而另外47名被打回原形的球员,平均出勤率为60.8场。
这些没有将上升趋势延续到底的球员,很多都是因为自身不够耐操,被伤病打断前进的步调。比如戴维斯(40场),比如迈尔斯-特纳(42),比如卢比奥(34),比如麦康奈尔(27)……
去年我们通过分析得出“追涨比抄底重要”,当时抄底的成功率只有4分之1。
一年之后,我们可以来验证这个结论是否还有效?
选出那些上赛季首月比赛后实时排名低于平均被选走顺位的球员,并且这些球员的平均被选走的顺位在100位后(因为想抄前100的底相对不现实,100后分段的球员流通性才更高),符合这份“抄底”条件的球员有83个。
而这83个球员最后赛季结算排名回到选秀时水平的有多少呢?15个。
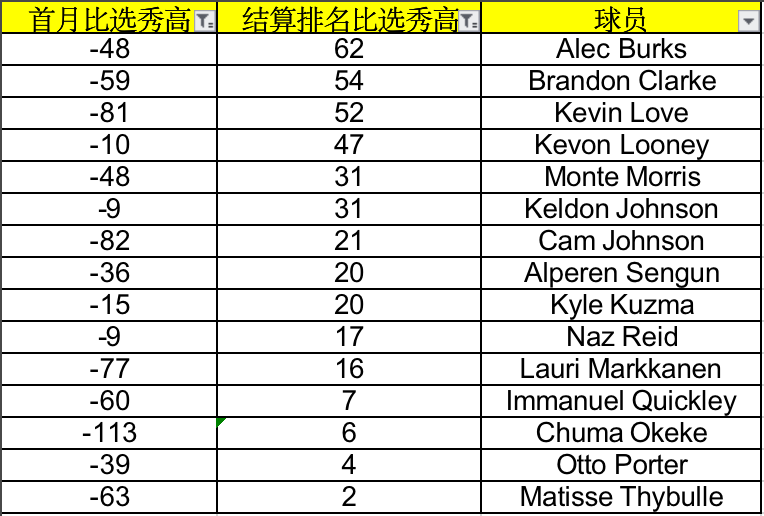
这大概是5.53比1的水平,“抄底”的效率甚至变低了,去年的结论仍未失效。
为什么“抄底”在范特西的难度极高?一方面在于这是个20个比赛周就归零循环的零和博弈,时间成本对实现价值回归并不友好。
另一方面在于,球队内部的用人轮换并不存在那么多严重的错判,当然有时候会出现被低估的球员,但大多数时候教练都对自己手底下的球员门儿清。
弃用某个球员基本上都有他过硬的逻辑:比如球员能力下滑,比如战术不合适,比如伤病……而这种时候首月排名的落差并不是估错价,而是基本面被破坏的讯号。

在这里又出现了一组有趣的相关性——抄底失败的球员和身价回暖的球员之间,出勤率同样有着明显的差异,前者平均比赛场次是56.4,而后者高达71.5。
但是,我们不能根据这一现象就得出“出勤率高的球员更容易身价回暖”的结论。只能说,抄底失败有可能是因为球员遭遇伤病,降低了自身的出勤率,从而打不回原来的身价。
是的,在与数据有相关性的现象面前,我们很容易错误归因,然后得出一个并不具备说服力的结论。
也许有人会问:“那你前面说的出勤率,不也是错误归因吗?”
“你以总数统计球员的段位,那出场多的球员不就天然有优势吗?”
“场均25分的球员A打30场只贡献750分,场均15分的球员B打了60场贡献了900分,虽然后者会有更高的结算排名,可场均30分的前者才是更值得用更高顺位拿下的选择吧?”
但,真的是这样吗?
你真的会在靠前位置选一个场均25分,但只打30场的球员吗?
上赛季场均27.4分的欧文就是很好的例子,如果按“场均数据”的口径统计,那么欧文的排名高达第14,但把一个比赛纪录只有27场的球员作为建队的“首轮球员”无疑等于主动投降,如果大家都不犯错,我可想不出来这样的球队会有什么优势……

“简单的游戏”
我翻看上赛季的分析,看到最后一段我用了“思考游戏的本质”这个小标题,那是很长的一大段话,但我觉得其实可以用更简单的话来总结这个游戏的本质——这是个谁数据多谁就胜出的游戏。
那什么能生产数据?无非是上场的时间,以及效率。
换句话说,如果一个球员能比其他人得到越多的上场时间(所以出勤率并不是错误归因,实打实的出勤率的确能帮上忙),并且在单位时间里做越多的事情,那么他不就能比其他人产生更多的数据吗?
而且,如果你有越多这样的球员,那么你获胜的概率不就越大吗?
这个游戏好像就是那么简单。
只不过,玩家们各自有各自的信息迷雾,谁也无法在每一次决策中做出完美的选择,这就是范特西的难度所在。
想鹤立鸡群,实在是要靠一点儿运气。但只要尊重基本规律,一分钱买一分货(在每个位置选到价值匹配的球员),1+1=2(阵容的相性要匹配,如果是1+a,两个不同的东西不就没法计算了?)。
好像也不会差到哪儿去吧?


















